SEMICON Japan 2018
「SMART Technology フォーラム AI最前線」レビュー
AI活用をもっと手軽にして、あらゆる応用にイノベーションを
株式会社エンライト 伊藤元昭 2019年2月12日
Google、Apple、Facebook、Amazonなど多くのIT企業が独自半導体チップの開発に注力するようになった。競争力の高いサービスを提供し、ビジネスでの強みを盤石なものとするうえで、ITシステムの中核に据える半導体チップ自体に独自性と卓越性が求められるようになったからだ。
特に、各社の技術開発とビジネス創出の競争が最も激しい人工知能(AI)に関連の分野では、独自AIチップを開発していないIT企業の方が珍しいくらいの状況だ。AIを巡るビジネスはますます激化し、産業界を横断した大きな潮流を生み出しつつある。そして、こうした独自の半導体チップの開発を競うIT企業の動きの先で、半導体業界の未来が開かれようとしている。
SEMICON Japan 2018の2日目の12月13日に、米国大使館商務部協賛で開催された「SMART Technology フォーラム AI最前線」では、AIの権威がビジネスと技術の両面の動きを俯瞰。そして、AI産業の最前線で技術開発とビジネス創出に取り組む企業が未来を展望した。
深層学習は、半導体とインターネットに匹敵する技術
最初に、東京大学大学院 工学系研究科 特任准教授の松尾 豊氏が、「人工知能は人間を超えるか ― ディープラーニングの先にあるもの」と題して講演。AIの最新動向、特にディープラーニング(深層学習)を取り巻く状況について語った。これまでの人工知能の発達史を紐解き、その中での深層学習の意義を開設し、今後の技術開発の方向性を指し示した。さらに、こうしたAIの発展が、社会や産業をどのように変えていくのかについて解説した。
AIに対する世の中の関心は高まる一方だ。しかし、現状では、AIと言う言葉を誤解して使っている例も多い。IT化、デジタル化のことをすべてAIと呼んでいる人も多い。さらに、ビッグデータの活用をAIと呼んでいる場合もある。しかし、「情報処理技術のブレークスルーとなっている技術をAIとしてとらえれば、現在のAIとは、すなわち深層学習のことであると考えるのが正しいでしょう」と松尾氏は言う。深層学習は2015年に画像認識の分野で人間を超える精度での判断力を実現した以降も、進化し続けている。2018年は自然言語処理の分野で技術的な大きな飛躍があり、様々なユースケースで人間と同等以上の精度で自然言語を認識できるようになった。
「深層学習と言う技術は、変数を増やし、深い関数を使った最小二乗法のことであると言い換えることができます。最小二乗法は、離散データの傾向を直線で近似する初歩的な統計手法です。深層学習は、変数を増やし、何層にもわたって最小二乗法を重ねていくことで、より複雑な傾向を適切に近似できるようになったにすぎません。少ない食材、単純な工程でできる料理は少ないですが、食材が増えて工程を重ねれば多様な料理を作れるようになります。これと同じことです。汎用性の高い統計手法の発展型なわけですから、その効果は普遍的に活用できます」と松尾氏は言う(図1)。
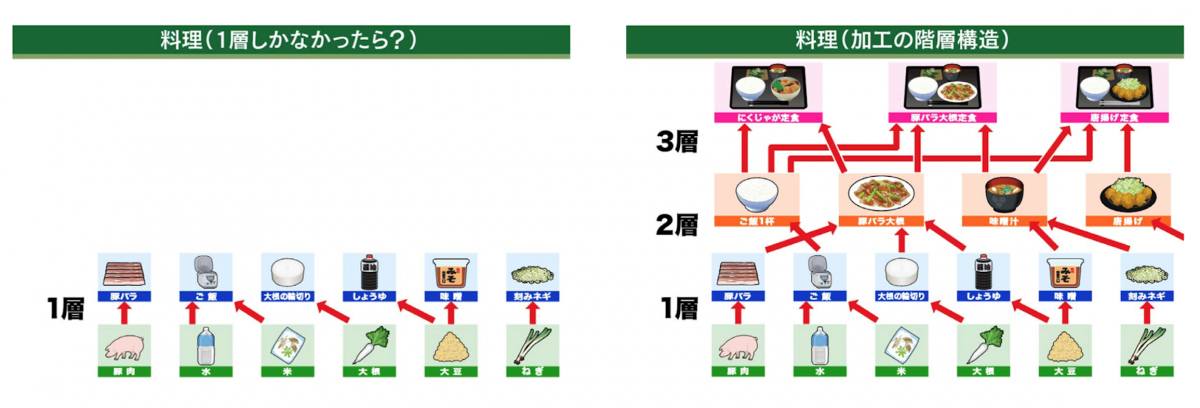
図1 深層学習の基本原理は、多くの食材を使い工程を重ねて多様な料理を作るのに似ている
出典:東京大学 松尾 豊氏
AIには、過去2回のブームがあり、その後沈静化してしまった。今回も単なる第3次ブームであるとみなす意見もある。しかし、松尾氏は、「単純な素子であるトランジスタの集積で複雑な処理を実行する半導体チップが出来上がり、単純な機器間通信の積み重ねでインターネットが出来上がりました。単純な最小二乗法の積み重ねである深層学習は、世の中に大きなインパクトを与えたこれらの技術に匹敵する、数十年に一度の技術だと考えています」とした。そして、深層学習のビジネスは、インターネットを活用して飛躍した多くのIT企業が生まれる直前の1990年代末の状況に酷似していると指摘。そのうえで、「日本企業は半導体産業の立ち上げには成功したが、インターネット関連産業の興隆の波に乗ることはできませんでした。深層学習でも出遅れていますが、今からでも挽回するように注力すべきです」と訴えた。
着々と進むエッジ側で実行するリアルタイムAIの環境整備
日本マイクロソフト 技術統括 執行役員 最高技術責任者の榊原 彰氏は、「豊かな社会を築くマイクロソフトの最新テクノロジー」と題して講演した。人の認知能力を超え始めたAIや、あらゆるモノからデータを収集しビッグデータ解析に利用可能にするIoT、現実と仮想の世界が融合させる複合現実など、最新技術によって社会がどのように変化していくのか。同氏は、マイクロソフトが保有する最新を例に取り、未来の社会を展望した。
現在、マイクロソフトは、エッジコンピューティングの環境整備に注力している。「Azure IoT Edge」と呼ぶ、クラウドと連携して動作するエッジコンピューティング用ソフトウエア環境をオープンソースとして提供。さらに、それを動かす「Windows10 IoT Core」と呼ぶチップを保有している。そして、エッジコンピューティングの適用分野を拡大するため、家電製品や産業機器、輸送機器への実装を想定した、「Azure Sphere」と呼ぶ小さくて軽いチップを新たに用意した(図2)。同社の家庭用ゲーム機「Xbox」で培った技術を注いで開発した、「ArmベースのCPUコアを搭載し、Linuxで動き、ネットワークに常時接続してセキュリティが維持できていることを監視し続けるチップです」(榊原氏)という。
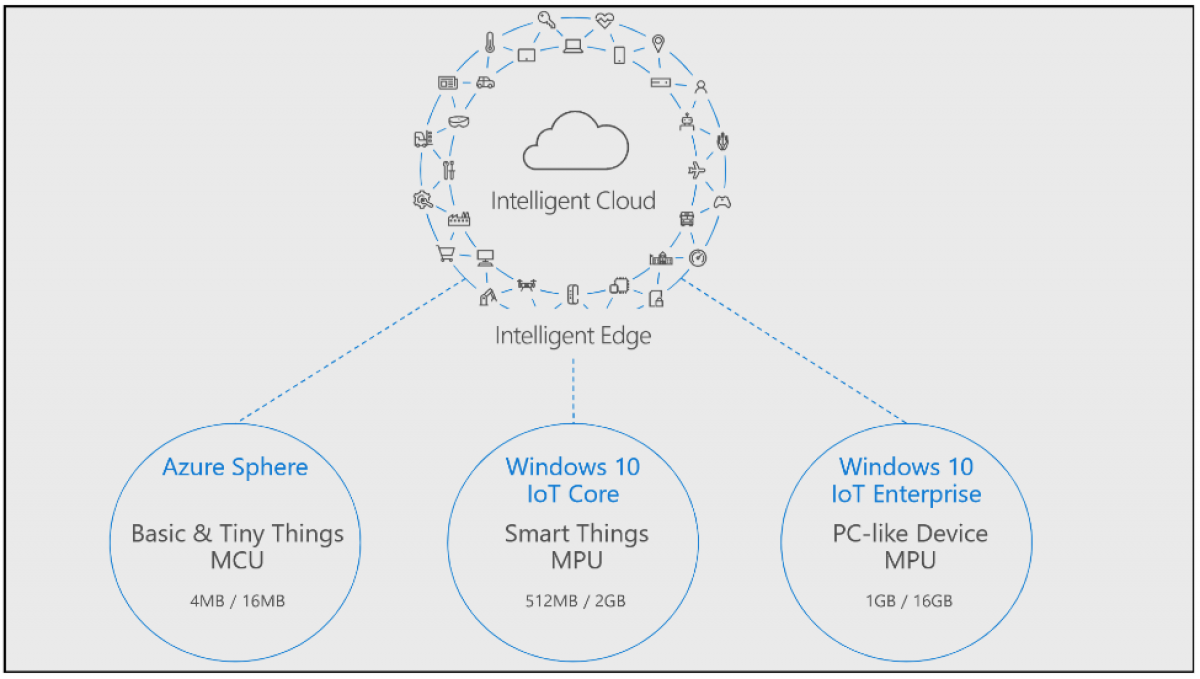
図2 マイクロソフトがエッジコンピューティング向けに用意した独自半導体チップの位置づけ
出典:マイクロソフト
マイクロソフトは、エッジ側でネットワークによる遅延がない推論処理を行う、リアルタイムAIの実現に向けた準備を着々と進めていると言う。現在、FPGA上にニューラルネットを実装した「BrainWave」と呼ぶアクセラレータをデータセンター側に置き、検索サービス「Bing」の検索処理と並行してランク付けの推論処理を実行している。既に、北米のデータセンター中のFPGAを使えば、Wikipedia中の英語で書かれた500万記事をスペイン語に翻訳するのに2秒しか掛からないほどの能力を実現しているという。そのBrainWaveを「エッジ側にも実装します」と榊原氏は言う。これによって、タンクから大量のトウモロコシの粒を流し出す際に、一粒一粒を検知してカビが発生した粒を選り分けることができる。
低コスト、高効率で使い勝手に優れたAI活用のインフラを提供
Amazon Web Services ML Solutions Lab Sr.AI Solutions ArchitectのSunil Mallya氏は、「Machine Learning in the cloud and on edge devices with Amazon Web Services」と題して講演した。現在、最もポピュラーなAIのフレームワークである「TensorFlow」の80%以上がAWS上で動いているという。同氏は、AIを活用したアプリケーション開発の重要なインフラになりつつあるAWSの現状と今後の展望を語った。
AWSでは、クラウドサービスを活用する際のAPIとして機械学習の機能を提供している。サービスには3階層がある(図3)。最も上位の階層は、画像認識や言語処理といった定まった応用での活用であり、アプリケーションの開発者が機械学習の知識がなくても利用できるようにしている。中間の階層は、エンドツーエンドでの機械学習のプラットフォームであり、機械学習応用の開発者やデータサイエンティストが開発したモデルを展開して試すような用途に活用する。最下層は、TensorFlowや「mxnet」「Chainer」といった機械学習のフレームワークであり、研究者や大学が利用する。学習や推論の処理は最新のCPUやGPU、FPGAを使って高速処理できる環境を提供している。
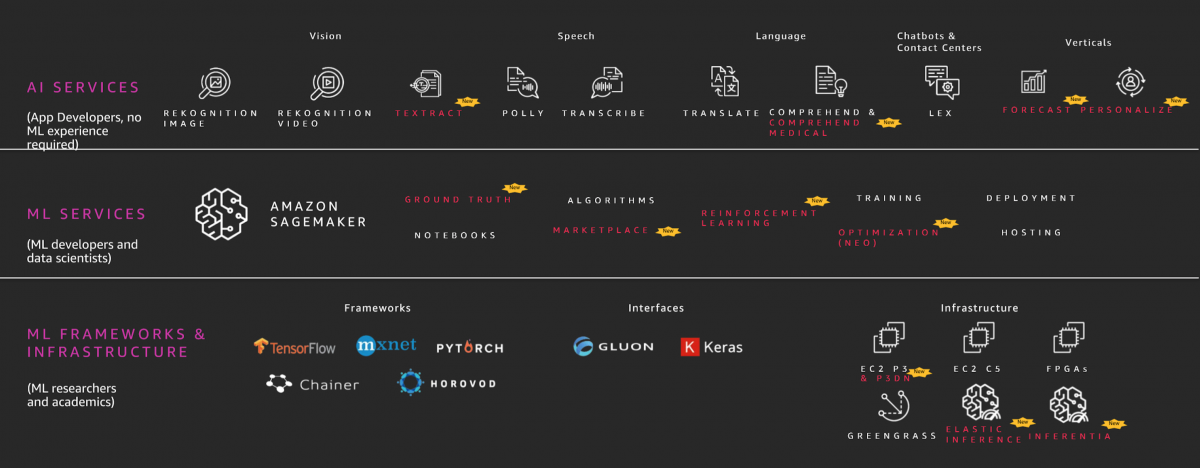
図3 AWSがクラウド上で提供している3階層の機械学習向けサービス
出典:AWS
「機械学習のアプリケーション開発には、3つの課題があります。コスト、データ、使い勝手です」とMallya氏は言う。
AWSでは、クラウドでの従量課金方式の価格体系を採用している。処理環境の高速化と増強を継続的に行い、フレームワークの最適化も進めている。加えて、「AWS Inferentia」と呼ぶGPUよりも高性能な独自チップも開発し投入している。これらの方策によって、極めて低コストでAIを活用したアプリケーションを開発・運用できる。機械学習のプラットフォーム「Amazon SageMaker」では、高性能なアルゴリズムがビルトインされているため、モデル開発に要する期間を従来の数カ月から数日に短縮できる。
機械学習に不可欠なデータを準備する作業を効率化するため、「Amazon SageMaker Ground Truth」と呼ぶ仕組みを提供している。機械学習のデータを集め、データを加工したり、ラベル付けしたりする作業を自動的している。これによって、短期間かつ低コストで効果的なデータを大量に用意することができる。
使い勝手を向上させるためには、エッジ側で推論処理するアプリケーションに向けて、フレームワーク上で開発したモデルをIntelやArmのCPU、NVIDIAのGPU、XilinxのFPGAなどターゲットチップに合わせて最適化するコンパイラ「Amazon SageMaker Neo」を提供している。さらに、データ収集が困難なアプリケーションを開拓するため、強化学習向けプラットフォーム「Amazon SageMaker RL」も投入した。
AI活用の最も泥臭い作業、データの収集・整理を効率化
DifinedCrowd 最高ビジネス開発責任者 兼 ジェネラルマネージャー(アジア担当) のAya Zook氏は、「AIの活用を可能にするデータの準備 市場投入までの時間短縮」と題して講演した。AIを有効活用するために最も大切な作業は、データの準備と前処理である。しかし、この作業は泥臭くて、手間が掛る作業でもある。AIで扱うデータを準備する部分にフォーカスしたビジネスを展開する同社が、AI活用の要所とそこでの効果と効率を高めるための方策を語った。
自社保有するデータを活用して、付加価値の高いビジネスを創出したいと考える企業は多い。その際、いかに迅速に、自社データを整えて資産化し、AIのプラットフォーム上で活用できる状態にするかが勝負になる。ただし、こうした作業は、思いのほか円滑に進まず、効果的なAI活用につなげることも難しい。
普及し始めたスマートスピーカを使った時、的確に会話できずにがっかりした人もいることだろう。これは、デバイスの能力不足やアルゴリズムの洗練度が劣っていて、円滑な会話ができないわけではない。学習時のデータの量と品質に問題があるため、起きている問題なのだ。ノイズのない、高品質なデータを、いかに大量に準備できるかが、AIを応用した製品やサービスの成否を決める(図4)。データの整理に際しては、適切なフォーマットで構造化し、優先順位を明確にし、プライバシーにも配慮しておく必要がある。
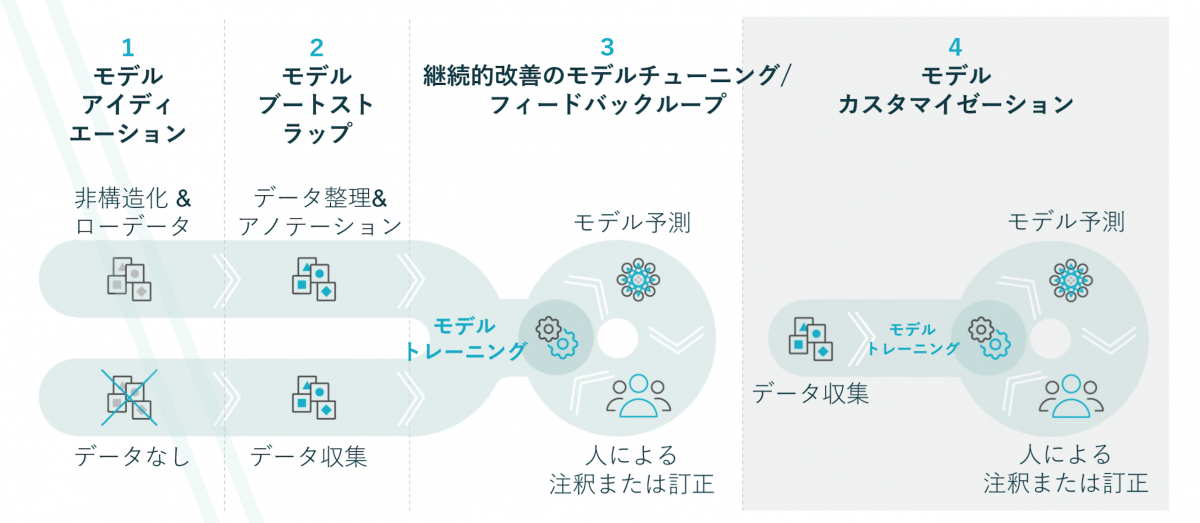
図4 高品質のデータを用意して効果的なAIモデルを作るための工程
出典:DifinedCrowd
ただし、質の高いデータを大量に用意するには、相応のコストと時間が掛かる。現在のデータサイエンティストは、80%の時間をデータクレンジング(データの整理と加工)に使っている。ここをいかに効率的かつ効果的にするかがAI活用の要所になる。Aya氏は、「日本には、価値あるデータがたくさん眠っています。しかし、そのままでは活用できないものがほとんどです。私たちは、機械学習とクラウドソーシングを活用して、ユーザーが多少のデータを追加すれば迅速に活用できる、質の高いデータを提供します」と言う。