RITdb is a semiconductor manufacturing database project organized as a Working Group under SEMI’s CAST (Collaborative Alliance for Semiconductor Test) Technology Community. Originally, RITdb was the “Rich Interactive Test Database” and the original goal was to create a shared architecture that supports smart adaptive testing for semiconductor makers by providing ready access to integrated, consistent, easy-to-use data across the entire manufacturing and test process. Figure 1 illustrates this process for making integrated circuits and how RITdb will collect data from the entire manufacturing flow.
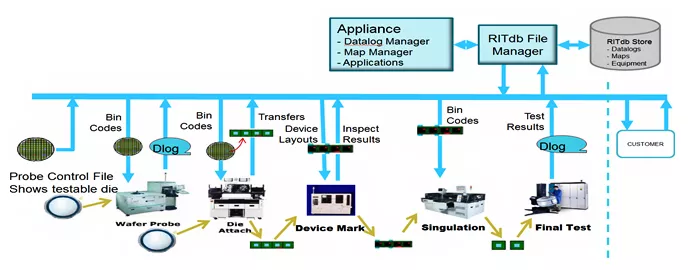
Figure 1: Manufacturing Flow for Making Integrated Circuits
RITdb’s end goal is to enable access to any sort of manufacturing data across the life of a product from inside or outside of the factory that made the product.
Adaptive test has two scopes:
- The Historical Scope: Make disparate data obtained from many different sources available on demand while dealing with issues of sharing, trust, and data security amongst all database users.
- The Immediate Scope (Now): Enable real-time decision making about processes and parts moving through the manufacturing process based on process history, results, and feedback.
Figure 2 illustrates a manufacturing flow that takes advantage of the RITdb database to make real-time decisions based on test results for devices as they move onward from the immediately preceding process step and from rules that have been developed over multiple manufacturing runs using previous test data in the historical manufacturing record.
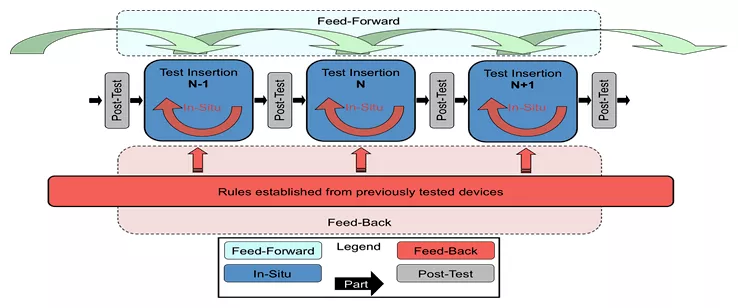
Figure 2: Real-Time Manufacturing Flow that Makes Decisions based on RITdb data. Image Source: IEEE Electronics Packaging Society HIR (Heterogeneous Integration Roadmap)
One of the development issues that the CAST RITdb Working Group has wrestled with is how to make data as easy to extract from the database as it is to put into the database. Many previous manufacturing database development efforts have stumbled over this goal, yet it’s imperative that data be easily accessible if it’s to be used for real-time decision making.
The end goal is for RITdb to become an “interplanetary” file system, which means that the database should be distributed over both time and distance. It should be available everywhere it’s needed. In addition, the data in the database has attached metadata to permit content-aware access. The metadata allows a data-consuming application to extract just the data it needs from the database, which reduces the amount of traffic over the manufacturing networking system and speeds database transactions.

Further, the database must maintain data integrity, which means that it uses hash-based naming and immutable files to make the data easy to find, so that the data-consuming application knows that the data it obtains from the database is correct, and to prevent data deletion. The database must also be secure, with access controls and encryption to protect data. Finally, the RITdb database employs versioning so that any changes made to the database can be easily tracked and traced over time.
RITdb Goals
The RITdb project has been driven by several goals:
- Enable plug-and-play database access so that many types of testing tools can feed data into the database in support of diverse test and manufacturing applications.
- Support generation of and access to real-time streaming data as well as to data previously stored in the database.
- Allow data from different producer tools to be merged, synchronized, and then delivered to data-consuming applications.
- Permit new data types to be easily added to the database without adversely affecting the existing database model. This goal allows new data types to be added to the database even before there’s an idea of how to use this new data.
- Integrate cleanly with the Adaptive Test Model.
The Data in the Lake
To meet all of these objectives, RITdb employs a “data lake” instead of a “data-warehouse” model. The data-warehouse model is a more traditional “big data” approach to databases where data is cleaned and normalized when it’s imported into the one, large database. A database using the data-lake model stores a pool of disparate but related data, which is cleaned and normalized at the point of creation. This approach better serves the goals of the RITdb database project by allowing real-time decision making based on prepared, good data with provenance.
Data provenance encompasses many data characteristics that require answers to many questions regarding:
- Identity: What is this data?
- Integrity: Who created this data, where was this data created, and is this truly the data that was created?
- Security: Who can access this data?
- Locality: Is this data grouped with other data based on some characteristic?
- Lineage: Where did this data come from?
In addition, RITdb incorporates other features to satisfy the “Now” scope. It supports a streaming data-flow model using RITdb packets and events. It uses a real-time messaging infrastructure based on IOT bidirectional, machine-to-machine communications and the MQTT (Message Queuing Telemetry Transport) protocol, an ISO standard (ISO/IEC PRF 20922) for publish-and-subscribe messaging, and the CBOR (Concise Binary Object Representation, a serialized, binary data format loosely based on JSON) format for payload data within the messages. Finally, the RITdb streaming protocol permits real-time rules checking so that an application program can look at data streaming in from a test cell and make real-time decisions based on that data.
Currently, planned submission for RITdb specification to SEMI for balloting is scheduled for 1Q19. To learn more about the SEMI CAST Technology Community, its RITdb activity, and/or to engage in this effort, please contact Paul Trio, senior manager of Strategic Initiatives) at SEMI, at ptrio@semi.org.
Stacy Ajouri is a systems integration engineer at Texas Instruments.